| NeuroScript MovAlyzeR Help | Send comments on this topic. |
Glossary Item Box
| NeuroScript MovAlyzeR Help | Send comments on this topic. |
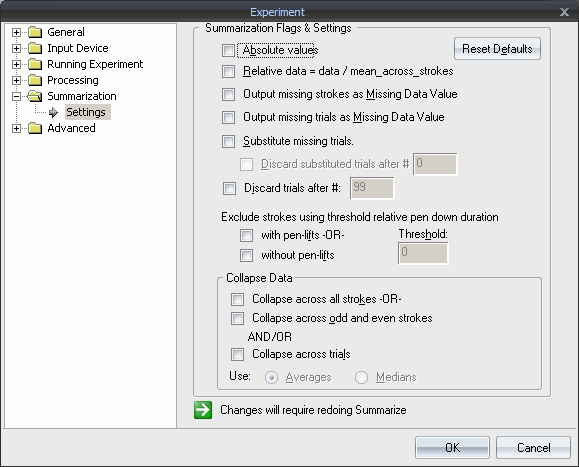
Processing
Summarization Settings
During Summarization, consistent trials from all conditions, subjects, groups are combined into one .inc file to perform data analysis or exporting to an independent statistical package. Refer the section on Summarizing All subjects for the procedure.
IMPORTANT
Summarize re-performs consistency checking of all trials being summarized. So for a set of processed trials, the .CON file (consistency file) created after processing is deleted in the summarize step and regenerated. This enables the user to change consistency settings before summarization without having to reprocess all trials.
Absolute Values: Up and down strokes show positive and negative signs for sizes, velocities, and accelerations. Absolute values remove these differences allowing to average across up and down strokes.
Relative Data = data / mean_across_strokes: Data can be normalized by dividing by the average across strokes within one trial to cope with overall trial variations in size or duration.
Output missing strokes as Missing Data Value: For statistical packages, missing/discarded strokes may have to be substituted by zero data so that the number of data lines per subject is constant.
Output missing trials as Missing Data Value: For statistical packages, missing/discarded trials may have to be substituted by zero data so that the number of data lines per subject is constant.
Substitute missing trials : In learning experiments where it is important to have a complete sequence of trials, it can be detrimental to the data when averaging across subjects per trial, if subjects now and then miss any of the trials in the sequence. To prevent this, missing trial can be substituted per subject by repeating the last trial (or in case the first trial is missing, substituting by the first non-missed trial).
Discard Substituted trials after #: Trials after a specified trial number may or may not be used to substitute earlier missed trials.
Discard trials after #: Trials after a specific trial number may be discarded at any rate.
Exclude Strokes using threshold relative pen down duration
> with pen-lifts
> without pen-lifts
Strokes with pen-lifts or without pen-lifts maybe excluded from summarization. Strokes are determined to have penlifts if the value of RelativePenDownDuration is less than the value in the Threshold field. Similarly, strokes with RelativePenDownDuration greater than the value of Threshold are considered to be without pen-lifts.
Collapse Data
When summarizing (a selection of) the groups and subjects, all conditions, all trials, all strokes, and (a selection of) all stroke features and questionnaire answers, datasets easily become huge. The Analysis phase will average across many factors. These huge datasets can be prevented by collapsing data that are supposed to be not different.
Across strokes: Up and down strokes show positive and negative signs in some features so taking absolute values is recommended. The stroke number value will be set to 1.
Across up and down strokes separately: Since even in repetitive loop patterns up and down strokes are different it makes sense to analyze them separately. The stroke number values will be set to 1 (odd stroke numbers) or 2 (even stroke numbers). If in the experiment properties the consistency checking is set to drop initial downstrokes 1 will mean upstrokes and 2 will mean downstrokes.
Across trials: Average first across trials. Since different numbers of trials are consistent, the average across trials and then the average across subjects is not exactly the same as the average across trials and subjects.
Averages: (Default) Average across strokes and/or trials.
Medians: Take the median value of the strokes and/or trials. It is not recommended to take the median across writing patterns with different strokes, e.g., across and lelele pattern.
EXAMPLES
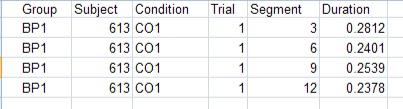
Without collapsing strokes or trials, the file of extracted data may look as (note that Segment number increases in steps of 3 because submovement analysis was selected, creating 3 parts per stroke: primary submovement, secondary submovement, and total stroke.)
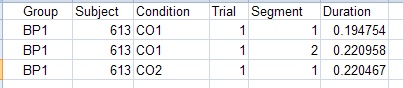
Collapsing across up and down strokes yields Segments 1 (odd strokes) and 2 (even strokes).
| See Also |
NSHelp: Summarizing | Processing Time functions | Processing Segmentation Settings | Processing Extraction Settings | Word Extraction
© NeuroScript LLC. All Rights Reserved.